Introduction
学术追星,kaiming亲自挂一作的文章。
先介绍一下无监督的特征学习,这个是NLP中比较成功的概念了,但是视觉领域因为图像的维度太高等问题还有待发展。 这篇文章讲的特征学习的方式就是利用无监督的方法来学习提取特征的方式, 举个例子,使用resnet50训练的时候,得到的结果就是最后那个1000维fc前面那个128维的fc,也就是学习了一种把图片encode成128*1向量的方式。 现在主流的视觉上的无监督特征学习的方法采用的是contrastive loss(观点来自于LeCun的一篇文章Dimensionality Reduction by Learning an Invariant Mapping 大概意思就是两个相似的样本,经过降维或是说特征提取之后仍然相似,反之),具体来说就是建立一个动态的字典,这字典会存有一些来自于encode数据集样本的keys, 我们需要训练一个新的encoder使其能够实现字典查询的功能,即encode一个新的样本,使其能够和字典中对应的key尽可能的相似,和别的尽可能的不同。
本文的主要观点就是通过队列(queue)的思想建立了一个动态的字典和一个缓慢更新的encoder,由此对contrastive learning中建立字典查找的方法进行了改进。 然后全面涨点,MoCo方法训练出来的无监督pretrained model在7个检测和分割的赛道上都超过的通过有监督学习学出来的模型。
Method
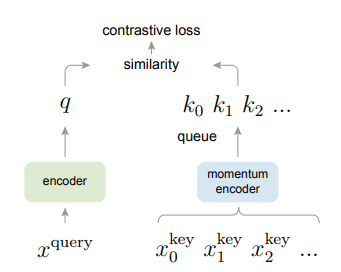
1. Contrastive Learning as Dictionary Look-up
假设有一个encoded query和一组含有encoded samples(k0,k1k2,…)的字典,k+指的是和q匹配的那个key,就可以构建一个类似于softmax的loss,这也叫InfoNCE loss,其中t是一个超参
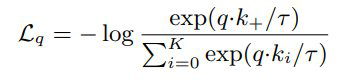
这个loss可以使匹配的key和query之间距离尽可能小,不匹配的key和query之间距离尽可能的大。
2. Momentum Contrast
-
Dictionary as a queue 使用队列的结构表示字典,具体来说就是一个batch的数量是n,那每次query encoder产生n个query,key encoder产生n个new key,在算上述loss的时候,除了有这n个query和n个new key,字典中还存有k*n个old key(源自于之前的batch存在字典里面的),这里的k是个超参,显然k越大字典越大,队列的思想就体现在当有一组new key产生的并且加字典的时候,就会有一组最旧的key被替换。(FIFO)
这样构建字典的好处就是将字典的大小和minibatch的大小隔离了开来,变成了一个可以调整的超参。 -
Momentum Update 通过上面那个图可以看到这个方法其实有两个网络构成,一个query encoder,一个key encoder,最naive的方法就是反向传播同时更新这两个encoder,或者说 他们共享weight,kaiming试了这个idea,但是不work,分析原因说是因为这样的话key的更新太快了,就减小了相互之间的一致性。
所以提出了动量的想法,其中下标q和k分表代表是query还是key的网络,通过这个方法就可以使得key encoder参数缓慢更新了。
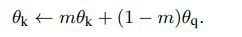
- Relationship to previous mechanisms
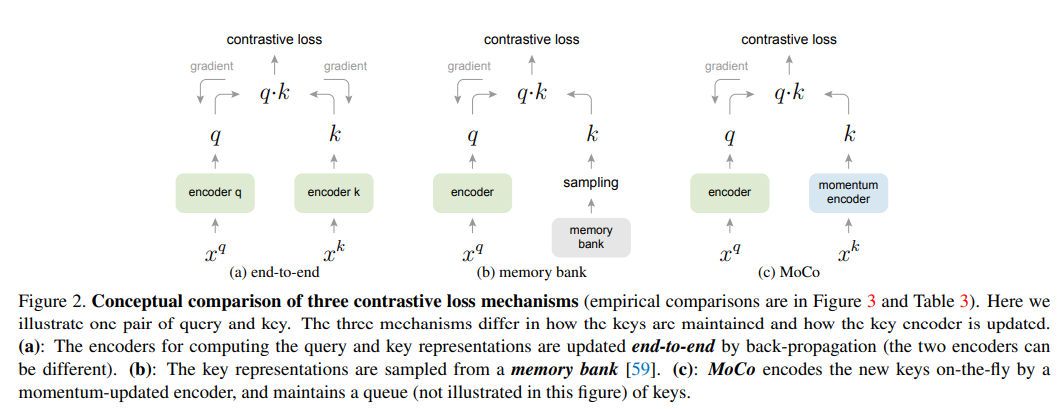
这里主要对比的之前end-to-end的方法以及menmory-bank的方法。和end-to-end的方法比无非是MoCo的字典变大了,而end-to-end会收minibatch大小的限制,如果minibatch变得很大,又会面临大bacth很难收敛的问题。和memory-bank比的话就是,memory-bank每次从bank中随机抽取一个batch拿出来算loss,然后算完在bank里面把这些替换成最新的query encoder生成的,就存在bank里面的key不是同一个阶段网络生成的问题,也就是前面提到的不够consistent的问题,所以效果不好。
3. Algorithm
这是论文里面提供的pytorch伪代码,讲的应该是非常清楚了。提一下contrastive learning其实有很多不同的pretext task,这里主要关注的是instance discrimination task,意思就是同一张图片只和自己配对,和所属类别无关。
