Introduction
Domain adaptation is a particular case of transfer learning that utilizes labeled data in one or more relevant source domains to execute new tasks in a target domain.
Cited from “Deep Visual Domain Adaptation: A Survey” pdf
Domain Adaptation在分类问题上现在已经有了不少的paper,详情可看上面提到的那个survey,但是domain adaptation在分割问题上研究还不多,并且分割问题和分类问题又存在的很大的不同,前者是pixel-wise的而后者不是,下面就是对最近几年的关于分割问题的domain adaptation的paper整理。
Reading List
1.Revisiting Batch Normalization For Practical Domain Adaptation(2016arXiv) pdf
Method
这篇文章可以说是提升效果最明显最简单的domain adaptation的文章了,并且不受task的限制,只要是网络中存在BN,即可使用这个方法在target domain上重新计算新的BN层的mean和var从而达到domain adaptation的效果。
当然这个文章能取得这么好的效果主要靠的是BN层的对于层间数据规范化的能力,因为BN会对层间数据做一个channel-wise的归一化,然后再通过可学习的缩放和平移系数,使得每个层得到的输入都尽可能的服从相同的分布(假设都是高斯分布),这从一定程度上减小了对于数据集的依赖,也就减少了domain shift对网络的影响。但这里只用到了均值,标准差这两个统计数据,即使两组数据同均值,同标准差,他们并不一定同分布,所以有一些方法也会由此引入协方差矩阵,希望通过协方差矩阵来进一步规范数据(但引入协方差矩阵同样会面临新的问题比如计算量过大,本身NN的数据维度就很高,与之对应的协方差矩阵的又会是维度的平方大小),从而得到generalization的效果。个人觉得这其实是一个trade-off,即网络得到的数据var越低,那么网络的泛化能力就会提升,但是网络的业务能力也会随之下降。
2. Learning to Adapt Structured Output Space for Semantic Segmentation(2018CVPR) pdf
Assumption
文章的假设是,在语义分割的问题上,虽然不同数据集的图片会存在domain shift,比如真实图片和虚拟图片的差距,但语义分割的结果往往会具有相同性,例如排布,形状等。(论文原话:For instance, even if images from two domains are very different in appearance, their segmentation outputs share a significant amount of similarities, e.g., spatial layout and local context)
Method
文章主要提出了因为语义分割结果具有相似性,所以想要在output space上面构建一个相似性损失函数,但是如果直接用一些类似于SSIM的指标来构建损失函数,又无法表达这个复杂的相似性,所以很自然的借鉴了GAN的思想使用了一个dsicriminator,即利用网络来判断两个语义分割的结果是否属于同一个domain。
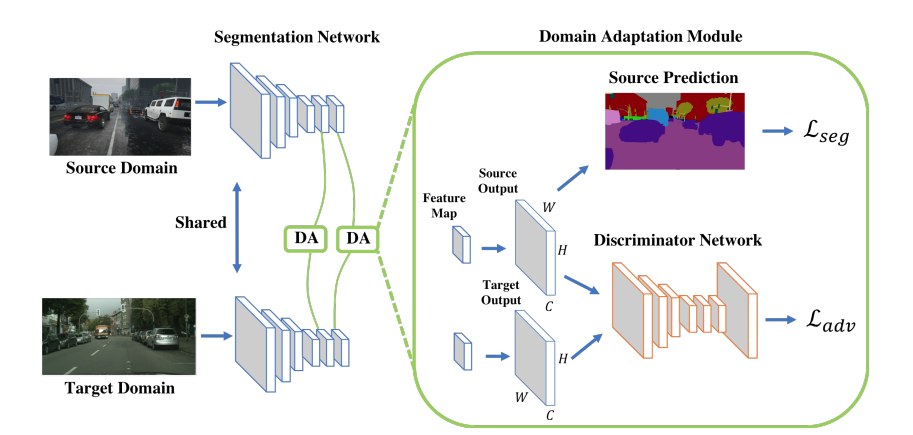 本文的核心观点就是这个output space上面的discriminator,但是为了实现SOTA,文章在featrue space上面也加了discriminator,通过这样一个加强的multi-level discriminator的模型,达到了SOTA的效果。
本文的核心观点就是这个output space上面的discriminator,但是为了实现SOTA,文章在featrue space上面也加了discriminator,通过这样一个加强的multi-level discriminator的模型,达到了SOTA的效果。
Result
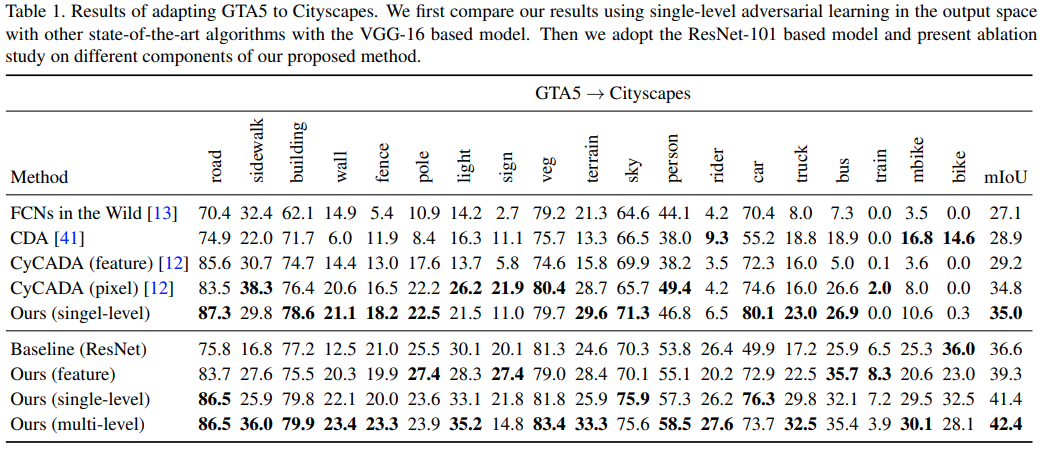
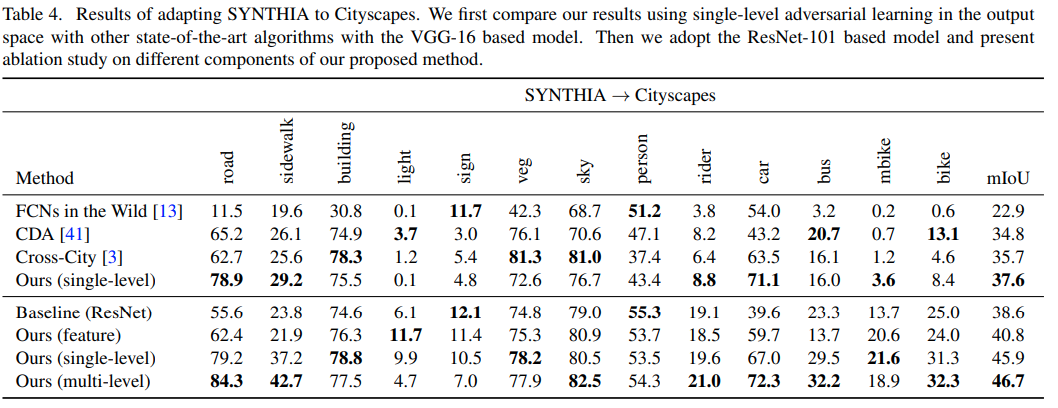
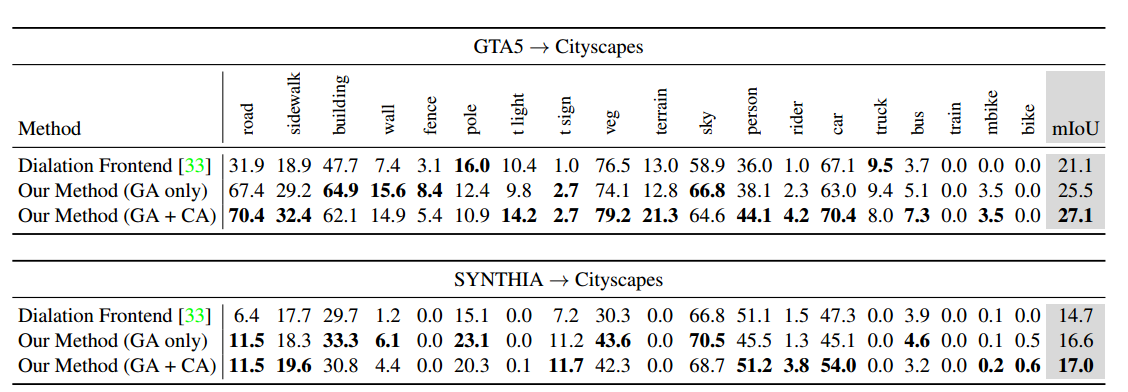
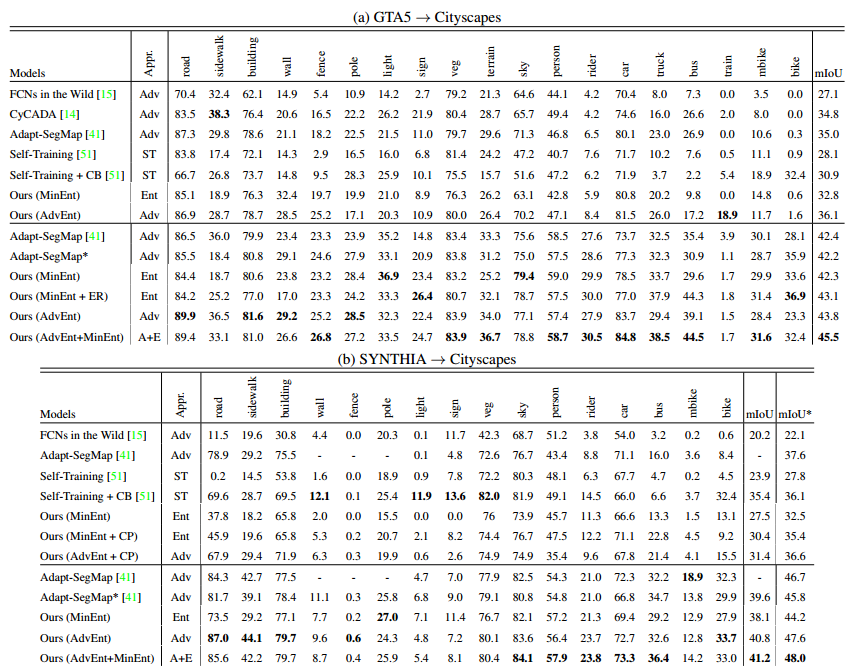
为了方便比较,只贴出GTA5->Cityscapes和SYNTHIA->Cityscapes这两组实验DA的结果
3. Conditional Generative Adversarial Network for Structured Domain Adaptation(2018CVPR) pdf
Assumption
这个文章的主要的观点是说如果一定要给两个不同的domain找一个common feature space太生硬了,所以需要给这个feature space一点弹性,所以提出了使用一个generator来学习两个不同domain的feature space的不同。
Method
文章的采用的结构如下
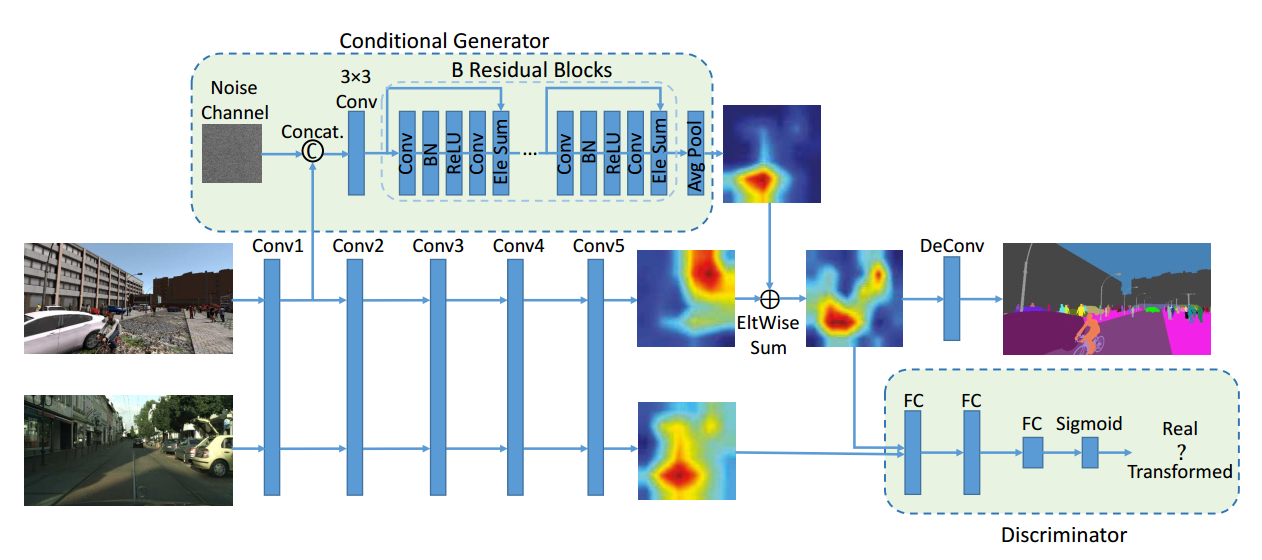 主要就是给source domain生成的feature map加了一个generator生成的residual feature map,两两相加之后送给discriminator和target domain的feature map做一个adversarial loss,来使得两个domain的feature map分布相近。然后这里提到之所以generator的输入是一个noise map叠加一个low-level feature map是因为noise map用来提供随机性,然后low-level feature map是用来提供一些底层的细节信息例如边界条纹等(一般来说CNN的前面几层都是在寻找一些边界信息),因为两两组合,就能生成较为合理的residual map。
主要就是给source domain生成的feature map加了一个generator生成的residual feature map,两两相加之后送给discriminator和target domain的feature map做一个adversarial loss,来使得两个domain的feature map分布相近。然后这里提到之所以generator的输入是一个noise map叠加一个low-level feature map是因为noise map用来提供随机性,然后low-level feature map是用来提供一些底层的细节信息例如边界条纹等(一般来说CNN的前面几层都是在寻找一些边界信息),因为两两组合,就能生成较为合理的residual map。
文章还专门提到,在实际训练这个模型的时候,我们把模型分为encoder,decoder,discriminator,generator四部分,那么一开始先用分割问题的cross entropy loss和实际上训练discriminator的loss来更新decoder和discriminator,然后固定住他们,再用adversarial loss来更新encoder和generator。并且考虑到GAN的不稳定性,所以实际上训练的时候,对于source domain的原始feature map和新生成的feature map都做segmentation loss。
Results
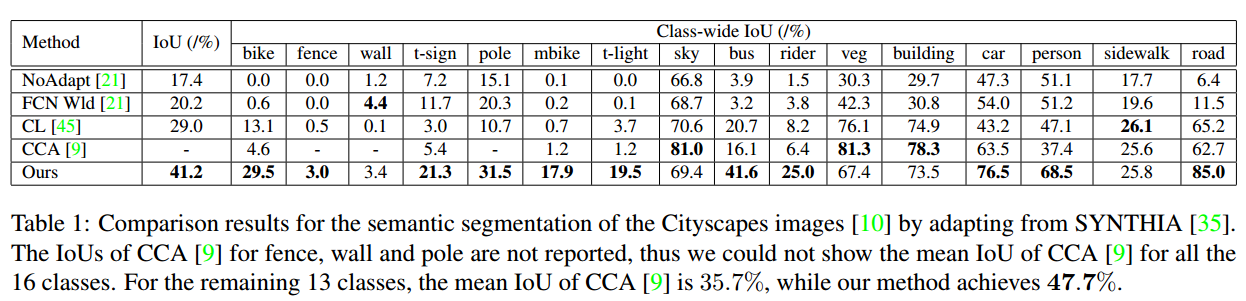
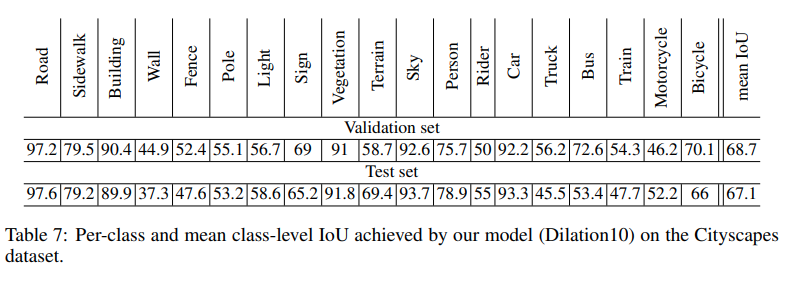
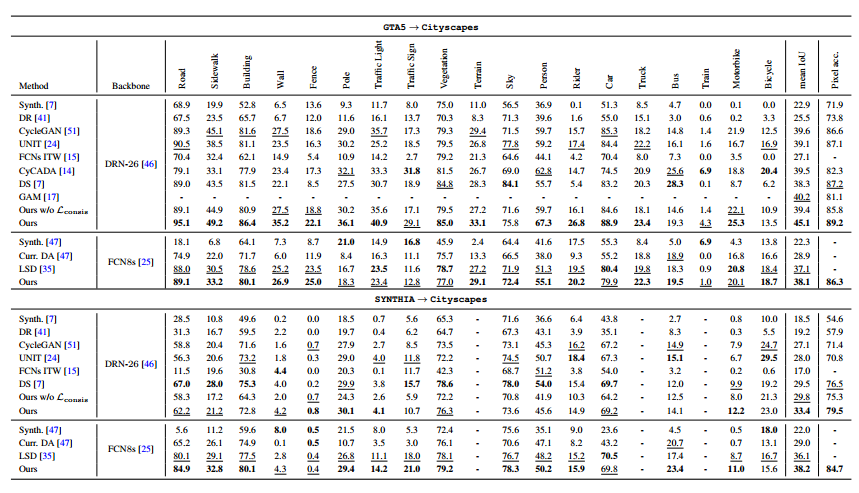
 可以看到这个方法涨点十分明显,可以说几乎在原来结果的基础上涨了50%的mIoU,最后的adaptation之后的模型在cityscapes上面的表现都超过了40%,但这里没有提供如果我们直接用FCN-8S这个模型在cityspaces上面直接用label训练的结果,也就是如果有label,那这个模型的极限能力在哪里,所以我查了一下cityspaces的benchmark,看到FCN-8s的表现是67.1%mean IoU,所以涨点到40看起来还是比较合理的,而且FCN-8s这个模型也没有BN层,所以也不存在是否使用了AdaBN辅助的问题。下图是FCN-8s模型在cityspaces上面的表现
可以看到这个方法涨点十分明显,可以说几乎在原来结果的基础上涨了50%的mIoU,最后的adaptation之后的模型在cityscapes上面的表现都超过了40%,但这里没有提供如果我们直接用FCN-8S这个模型在cityspaces上面直接用label训练的结果,也就是如果有label,那这个模型的极限能力在哪里,所以我查了一下cityspaces的benchmark,看到FCN-8s的表现是67.1%mean IoU,所以涨点到40看起来还是比较合理的,而且FCN-8s这个模型也没有BN层,所以也不存在是否使用了AdaBN辅助的问题。下图是FCN-8s模型在cityspaces上面的表现
4. FCNs in the Wild: Pixel-level Adversarial and Constraint-based Adaptation(2016arXiv) pdf
这应该是第一篇做pixel-level的doamin adaptation的文章(有一说一这个文章写的是真的烂,前言不搭后语的,提出的第二个loss也没有公式,写的乱七八糟,github上面也没有实现的代码,醉了)
Assumption
文章把存在的domain shift分成了两类global和category shifts,一个global是由于数据集整体的变化造成的特征空间的边缘概率的不同,这个domain shift在两个比较不同的数据集中比较明显,比如生成数据集和真实数据集;第二个category是每一个种类内部的参数变化造成的doamin shift,例如不同数据集同一类的东西的大小,外观,数量都会存在不同。
作者在这篇文章里假设不同的domain拥有相同的label space
Method
为了解决文章中提到的两个domain shift,作者用了两个loss来解决。对于第一个global domain shift,作者在最终输出层的前一层后面加了一个discriminator做了一个adversarial loss;对于第二个category domain shift,作者提出了一个针对每一个种类该有的size的loss,按照我的理解就是,在source domain里面,因为我们有label,所以可以统计每一类的大小,即每一类出现在每张图片里面占据图片的比例,举个例子,车载的那种道路分割图片(KITTI),即使真实数据集和生成数据集存在shift,但是车载摄像头拍的道路图片的主旋律就是道路占据图片比较大的空间,所以如果我们的模型在target domain上预测的道路部分只占了当前图片很小的空间,那么很大概率是这个预测存在问题,所以作者要根据在source doamin上每一类大小的统计数据,给他们在target domain上预测的实际size一个无监督的loss。
至于这个loss怎么实现的,怎么梯度更新的,文章没说,代码也没有,所以我盲猜是个0-1 loss吧,即预测的东西的大小如果符合统计范围内,就没有loss,如果不符合,就loss是1。然后文章提到因为一张图片里面的很多类大家有大有小,比方说车载图片,道路就是占地很大,行人可能就是占地很小,所以对于面积比较大的那类,梯度更新时会给一个0.1的scalar平均一下。(所以如果是0-1loss的话,面积大小我觉得没关系吧,不应该看大家的出现次数么,出现次数多的种类给一个小的scalar?不懂,总之这个category loss充满了迷幻现实主义色彩,大家看看就好,也可能是我英语阅读理解太抠脚,无法理解作者的深意,欢迎大家看原文然后深度解读一下)
文章还提到说因为这个category要比较target image预测的物体的size对不对,所以不太能在模型一开始训练的时候就把这个loss加进去,因为一开始模型一通乱预测,这个loss就会很大会把模型带歪,所以先在source domain上训好了在用这个无监督loss finetune的实际上是。这个观点我还是比较赞同的,无监督loss无论是进场过早还是系数过大,都会把模型带进沟里。
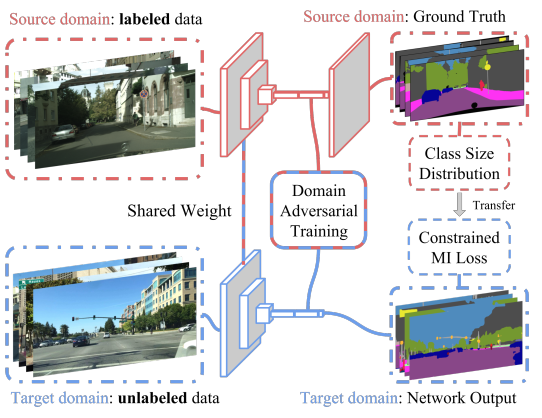 模型结构配图一张,结构上还是比较简单的。
模型结构配图一张,结构上还是比较简单的。
Results
(这个文章看的过于影响心情,随便贴两个结果了)
5.Curriculum Domain Adaptation for Semantic Segmentation of Urban Scenes(2017ICCV)pdf
这是找到的时间顺序上第二篇做DA for Segmentation的文章,文章的虽然有点老,但是其中的观点还是有点意思,相比于FCNS,文章不同或者说贡献主要是手动设计了两个loss function来增强model的generalize能力。
Assumption
文章的主要假设是觉得FCNS的方法是寻找一个common feature space,所以默认了不同的domains拥有同样的decision functions,这个假设存在问题,作者认为适应到target domain上,需要使得模型更加适应target domain的一些特性,基于这个假设,作者构建了两个target domain property的loss。
Method
作者主要提出了两个target domain properties,一个是Global label distributions of images,另一个是Local label distributions of landmark superpixels。所以整个模型的思路很简单,就是一个segmentation的cross entropy loss加上两个properties的各自的loss来联合训练模型。
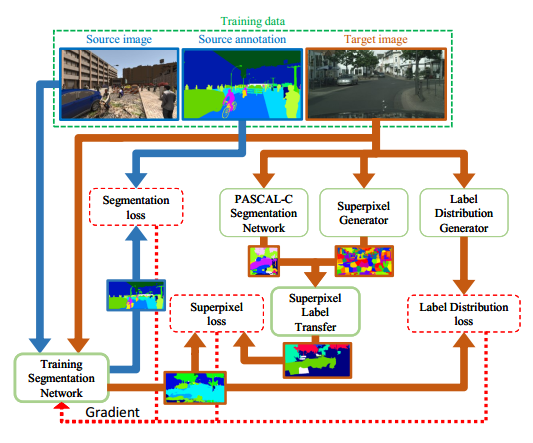 下面简单讲一个两个target domain properties:
下面简单讲一个两个target domain properties:
- Global label distributions of images 这个其实就是在FCNS那个size constraint loss上面的延伸,把每个图片中各个类别的占比用一个分布来表示,比方说,输入一张车载图片,其中天空占0.6,马路占0.3,行人占0.1,因此构成了一个[0.6,0.3,0.1]的vector,把所有的图片都统计一遍,就有了一个distribution,所以说target domain的预测结果,要符合target doamin的这个分布,所以问题来了,我们其实没有target domain的标注,所以没有label就只能自己造pseudo label,所以作者这里就用一个backbone的Inception-Resnet V2的model来提出特征,然后用传统ML算法logistic regression,Nearest Neighbour等在source doamin上面训练,然后在target doamin上直接回归单张图片的各类占比分布(这里就是假设说这个任务相对比较简单,所以受domain shift的影响比较小,但我这里这里可以做个实验验证一下,虽然intuitively来说是正确的)
- Local label distributions of landmark superpixels 第一个global label distribution缺少了对于位置信息的监督,所以第二个这个local label引入了位置信息,主要就是首先把图片分割成100个superpixels,然后通过在别的语义分割数据集上预训练的模型FCN来对于每一个superpixel块提取特征,然后再次根据source domain的label训练一个SVM用于预测每一个superpixel块的分布
- Loss
无论是global distribution还是local distribution,作者都通过生成的pseudo label和实际segmentation model生成的的结果算出来的分布,构建了一个entory+KL divergence的loss:
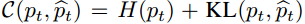
Results
主要在和FCNS进行对比,显示结果远超了FCNS,达到了当时的SOTA,并且说明了和FCNS使用了同样的model,但是baseline就远超FCNS(这个也make sense毕竟FCNS这个文章无比的随意)
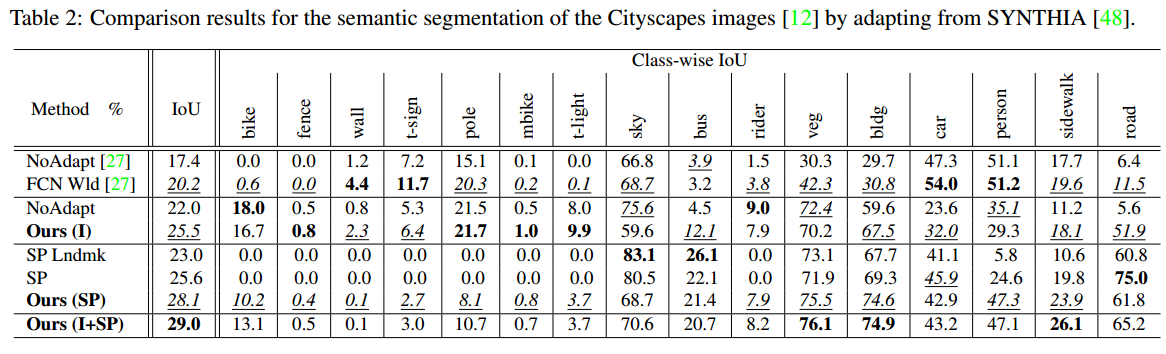
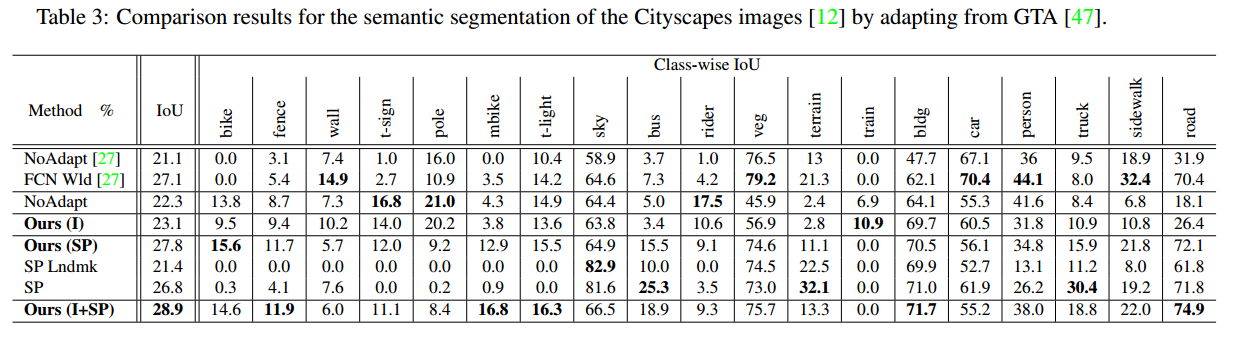 通过这个表可以发现引入了位置信息的SP loss涨点比较明显。个人猜想整体上的distribution来做loss,对于梯度更新来说比较模糊,所以可能效果不明显。
通过这个表可以发现引入了位置信息的SP loss涨点比较明显。个人猜想整体上的distribution来做loss,对于梯度更新来说比较模糊,所以可能效果不明显。
6.ADVENT: Adversarial Entropy Minimization for Domain Adaptation in Semantic Segmentation(2019CVPR)pdf
这个文章主要是在Learning to Adapt Structured Output Space for Semantic Segmentation这个文章的基础上进一步拓展了,加入了entropy map的概念以及加了个unsupervised loss,然后涨了一些点,成为了SOTA。
Assumption
文章的主要的假设和上面那篇文章一样,也就是不同domain的output还是存在一定的相似性的,所以可以用一个discriminator来拉进他们的距离。同时文章创新的地方就是引入了entropy的概念吧,segmentation map其实是对每一个像素点都做一个分类,softmax之后会得到了一个看起来很像概率的东西(虽然他们本质上并不是),如果我们认为这个就是概率,那么就可以通过一个公式(h,w代表map的高和宽,c代表有多少类)
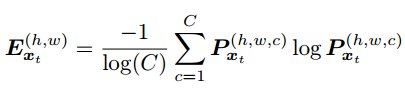
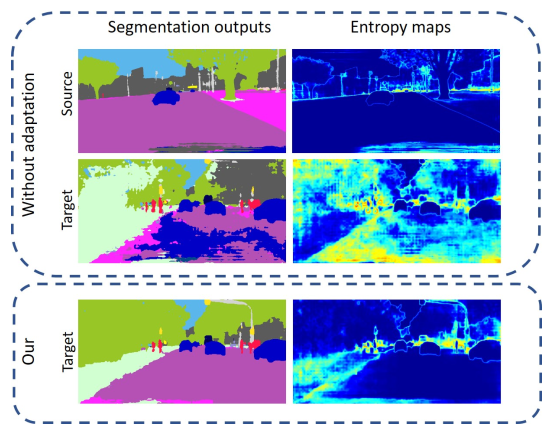
所以如果结果十分确定,举个极端例子,在某一个点上面,得到的结果是[1,0,0,0,0],意思是该点有100%的可能性是属于第一类,所以entropy算出来就是0,其实这个entropy就是看模型对于预测的结果是否自信。文章里面贴了个图,可以看到这个entropy map和segmentation map的区别就是仿佛entropy map在勾勒一个边界,也就是说,模型其实在边界处是没那么自信的,不知道边界到底该属于哪一类,所以entropy就会高一点。
Method
主要方法就是把模型输出的结果从一个segmentation map先转换成一个entropy map,然后用一个discriminator来对不同domain的entropy map做一个adversarial loss,然后辅助加上一个entropy minimization loss,这个loss的公式如下
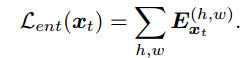 这个loss作者说还和self-training的概念有点相近,其实本质上在利用模型生成的pseudo label来进一步对模型进行训练,只不过相比于设置一些threshold来选取一些high-confidence pixel作为label,这个entropy的方法就类似于一个soft label。感觉就是稍微用了几句话简单了证明了一下他的观点可能是有理论依据的?反正听起来还是有点道理的。
具体的模型结构就是如下
这个loss作者说还和self-training的概念有点相近,其实本质上在利用模型生成的pseudo label来进一步对模型进行训练,只不过相比于设置一些threshold来选取一些high-confidence pixel作为label,这个entropy的方法就类似于一个soft label。感觉就是稍微用了几句话简单了证明了一下他的观点可能是有理论依据的?反正听起来还是有点道理的。
具体的模型结构就是如下
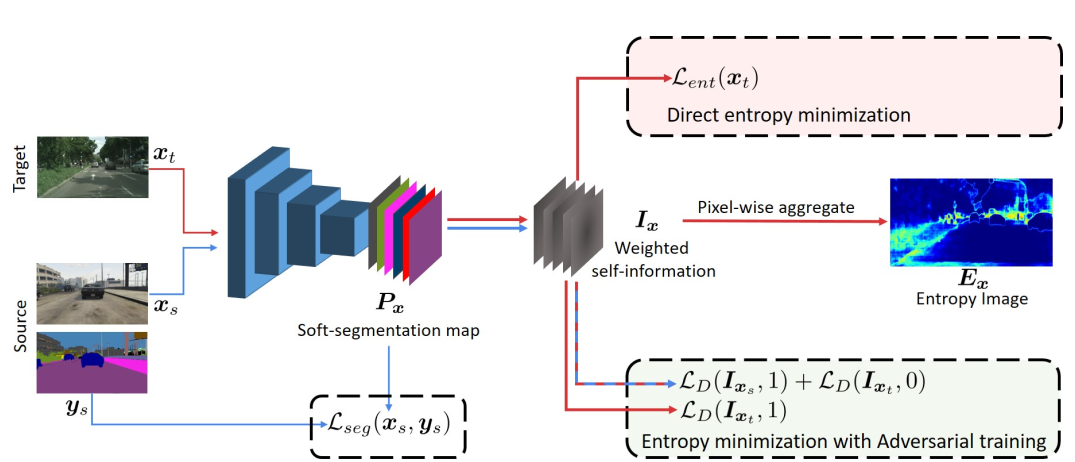 这里需要提一下的是,这个adversarial loss和cyclegan的不同,这里这个loss只是使得target domain的结果和source domain的接近,所以只针对target domain而不会去改变source domain的分布。
文章中没有提到具体的训练过程,只提到这个adversarial loss和entropy minimization loss的权重都是0.001,反正就是这种无监督的loss如果权重过大就很容易把训练带崩,所以我猜测这个模型也是用了在source domain上面训练好的模型来初始化。
这里需要提一下的是,这个adversarial loss和cyclegan的不同,这里这个loss只是使得target domain的结果和source domain的接近,所以只针对target domain而不会去改变source domain的分布。
文章中没有提到具体的训练过程,只提到这个adversarial loss和entropy minimization loss的权重都是0.001,反正就是这种无监督的loss如果权重过大就很容易把训练带崩,所以我猜测这个模型也是用了在source domain上面训练好的模型来初始化。
Results
这个文章主要是在Adapt Seg上面进行了延伸,所以也主要只和Adapt Seg进行了对比,可以看到基本上是涨点了吧,虽然可能没有那么明显。
7.DCAN: Dual Channel-wise Alignment Networks for Unsupervised Scene Adaptation(2018ECCV)pdf
这个文章没有细看,只是粗略的看了一个大概,主要就是手动用了改进版的instance normalization来进行pixel-level和feature-level的adaptation
Method
- Channel-wise Feature Alignment
这个文章的思路主要来源于style transfer,提到在style transfer领域,会有一个original image和一个reference image,然后我们就需要把original image的风格转移的尽量和reference相近,所以在这个领域大家都是用的instance normalization而不是batch normalization,然后也有一些文章提到其实图片的mean和var包含了大量色彩和纹理的信息,所以这两个参数其实对于图片的风格很重要(我当时也看到过这个,看完觉得make sense然后就没有然后了,这个大哥却由此发了个文章)。本文就是用Adaptative Instance Normalization来做一个Channel-wise Feature Alignment,具体细节如下
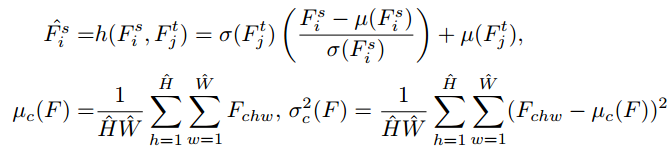 可以看到其实就是对于reference image算一个mean和var,然后把original image归一化之后放到reference image的参数里面,有种每层强行统一分布的感觉
可以看到其实就是对于reference image算一个mean和var,然后把original image归一化之后放到reference image的参数里面,有种每层强行统一分布的感觉 - Model
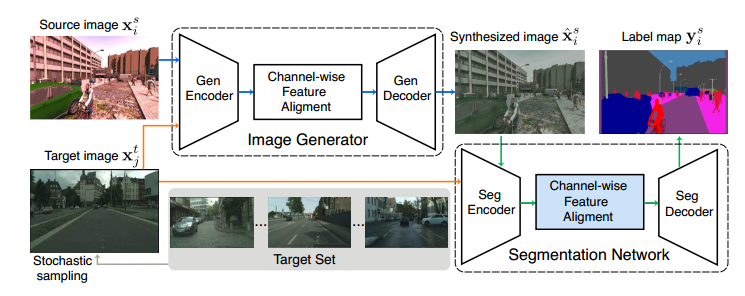 模型的结构就是这样,先是在target domain里面选一个reference image,然后先经过一个叫Image Generator的网络来进行风格迁移,这里风格迁移还有一个loss function就是用来比较迁移过后的图片和原来的图片还像不像,不要丢失过多的信息,这loss function如下,这里不细讲了不是重点,详情可见原文
模型的结构就是这样,先是在target domain里面选一个reference image,然后先经过一个叫Image Generator的网络来进行风格迁移,这里风格迁移还有一个loss function就是用来比较迁移过后的图片和原来的图片还像不像,不要丢失过多的信息,这loss function如下,这里不细讲了不是重点,详情可见原文
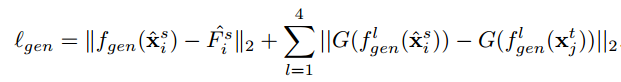 得到风格迁移过后的图片就送进segmentation network,这里面又对segmentation network再次做了一个Channel-wise Feature Alignment然后就得到结果并且进行正常的segmentation loss
得到风格迁移过后的图片就送进segmentation network,这里面又对segmentation network再次做了一个Channel-wise Feature Alignment然后就得到结果并且进行正常的segmentation loss
Results
结果如下,这个文章还给了Oracle的结果也是很令人感动
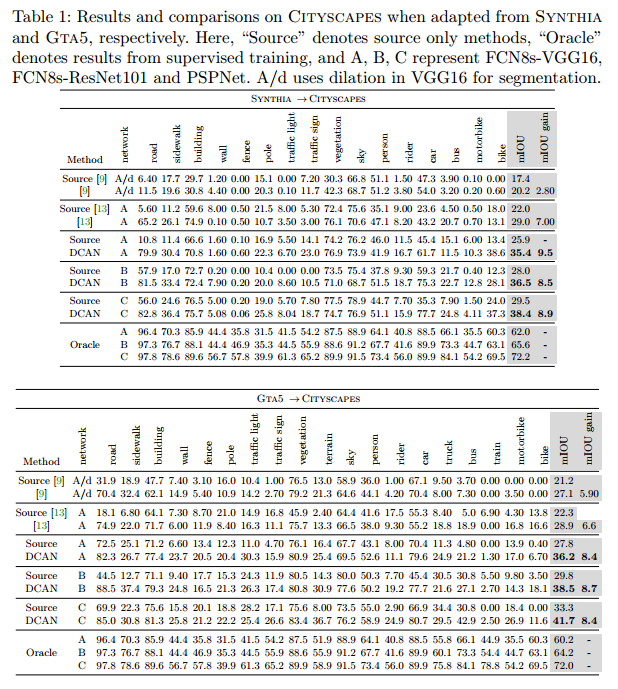 文章里实验还是做的比较详尽的,还使用别的image synthesis methods来对比试验,说明Channel-wise Feature Alignment真的会有帮助
文章里实验还是做的比较详尽的,还使用别的image synthesis methods来对比试验,说明Channel-wise Feature Alignment真的会有帮助
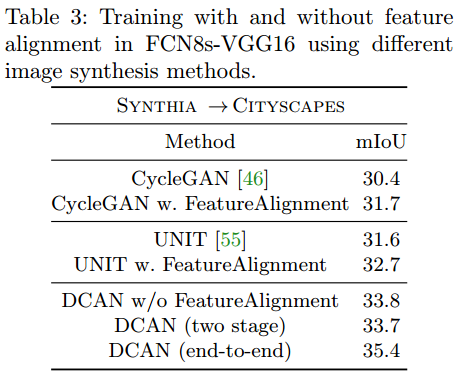 同时也用了别的segmentation network上面feature alignment的方法来和Channel-wise Feature Alignment对比,说明Channel-wise Feature Alignment效果最好
同时也用了别的segmentation network上面feature alignment的方法来和Channel-wise Feature Alignment对比,说明Channel-wise Feature Alignment效果最好
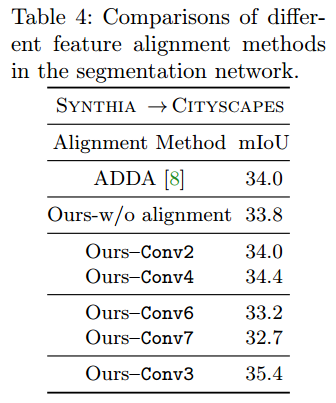 这里首先是ADDA(用了一个discriminator来align feature space)比较,说明Channel-wise Feature Alignment效果更好,然后分别演示在哪一层后面用这个Channel-wise Feature Alignment效果最好,发现是conv3后面,作者的分析是conv3后面channel(256)数和feature map(1/8)大小都比较合适,然后conv6,7效果最差因为这两层太后面了所以downsample过多feature map太小,所以说明我们在alignment的时候需要保留具体的空间信息。同时作者也尝试了MMD和CORAL的方法都是结果都太差了不仅没有涨点还掉点了所以就没把结果贴出来,这其实也和组里实验一致。
这里首先是ADDA(用了一个discriminator来align feature space)比较,说明Channel-wise Feature Alignment效果更好,然后分别演示在哪一层后面用这个Channel-wise Feature Alignment效果最好,发现是conv3后面,作者的分析是conv3后面channel(256)数和feature map(1/8)大小都比较合适,然后conv6,7效果最差因为这两层太后面了所以downsample过多feature map太小,所以说明我们在alignment的时候需要保留具体的空间信息。同时作者也尝试了MMD和CORAL的方法都是结果都太差了不仅没有涨点还掉点了所以就没把结果贴出来,这其实也和组里实验一致。
总之这篇文章还是写的蛮好的值得一读,发现ECCV的文章感觉都比CVPR的看上去写的好一点,不知道是不是我的错觉。。。
8.CYCADA: CYCLE-CONSISTENT ADVERSARIAL DOMAIN ADAPTATION(2018ICML)pdf
这是FCNS文章作者接着的第二篇同领域文章,相比于上篇,写的真的好太多,可能是因为这个投稿了而上一篇只是arXiv吧,这篇文章基本上就是根据CycleGAN把GAN在domain adaptation上面用到了极致,没有细看,所以大概讲讲文章的方法吧。
Method
文章的思路不难,先贴个模型图
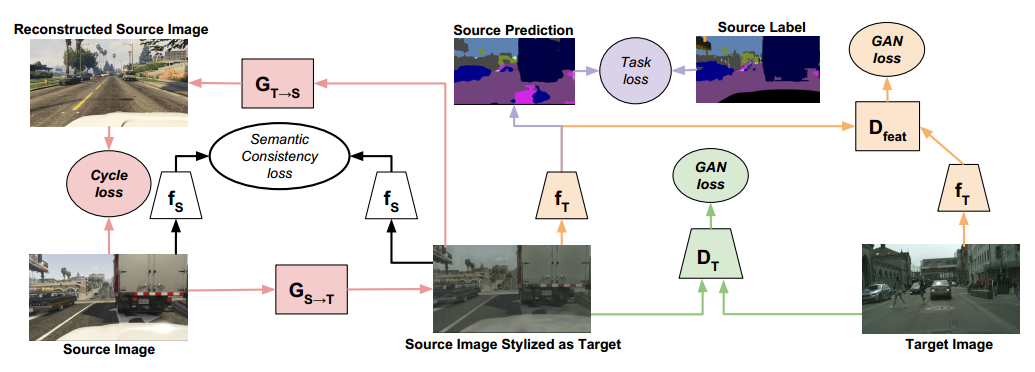 从图片可以看出,首先有一个image translation的网络(图中两个G),这就是一个cyclegan的网络,同时在feature space上面也加了个GAN loss,对于生成的Source Image Stylized as Target和原始的source image还做了一个sementic consistency loss,别的loss不多说了就是GAN那套,简单讲讲这个consistency loss,先贴公式
从图片可以看出,首先有一个image translation的网络(图中两个G),这就是一个cyclegan的网络,同时在feature space上面也加了个GAN loss,对于生成的Source Image Stylized as Target和原始的source image还做了一个sementic consistency loss,别的loss不多说了就是GAN那套,简单讲讲这个consistency loss,先贴公式
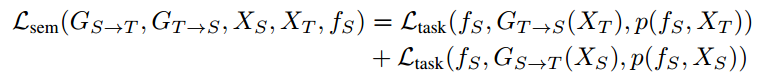 简单解释一下就是先拿一个在source domain上面训练好的模型f,然后直接拿source和target domain的原图送进去得到一个segmentation map,argmax之后把这个结果作为我们的gt,然后再拿G分别生成的新图,送给f然后拿结果和我们刚刚生成的gt来做cross entropy loss
这个模型还是相对比较复杂的,光是loss都写了一大串
简单解释一下就是先拿一个在source domain上面训练好的模型f,然后直接拿source和target domain的原图送进去得到一个segmentation map,argmax之后把这个结果作为我们的gt,然后再拿G分别生成的新图,送给f然后拿结果和我们刚刚生成的gt来做cross entropy loss
这个模型还是相对比较复杂的,光是loss都写了一大串
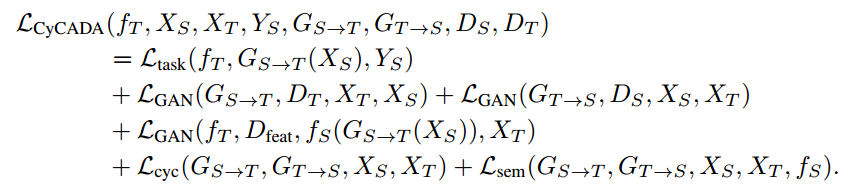
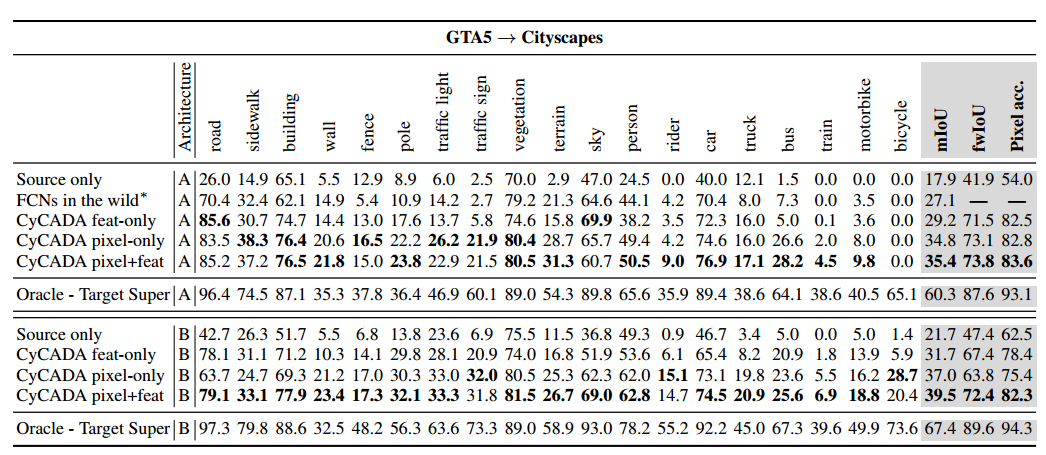
Results
随便贴个结果,反正和他原来的方法比是涨点了,用的模型就是FCN8s-VGG16
9.CrDoCo: Pixel-level Domain Transfer with Cross-Domain Consistency(2019CVPR)pdf
看这个名字,就知道和CYCADA上一篇差不多,确实也是如此,这个文章就是在上一篇的基础上进行了一些修修补补的工作,且针对consistency loss进行了五毛钱创新
Method
直接上模型图
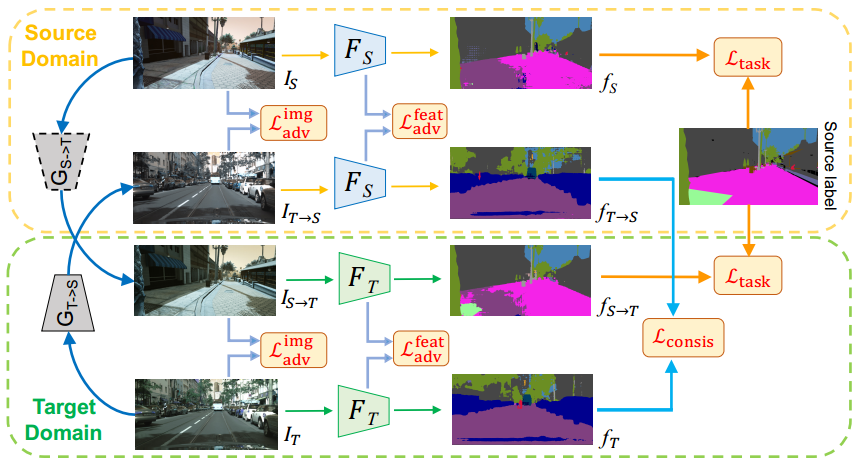 可以看到和cycada的结构基本上一样,唯一的不用就是大家的consistency loss不同,这里作者直接对比target domain image和生成的target domain image的segmentation maps对了一个双向的KL-divergency的loss,意思是这两个segmentation maps应该是一样的,公式如下
可以看到和cycada的结构基本上一样,唯一的不用就是大家的consistency loss不同,这里作者直接对比target domain image和生成的target domain image的segmentation maps对了一个双向的KL-divergency的loss,意思是这两个segmentation maps应该是一样的,公式如下
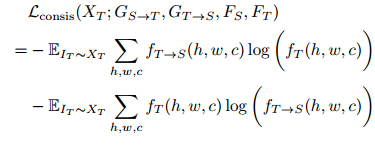 (其实我觉得文章这个loss可能还写错了,按照这个式子,这个不是bi-KL而是一个bi-cross entropy)
(其实我觉得文章这个loss可能还写错了,按照这个式子,这个不是bi-KL而是一个bi-cross entropy)
Results
从表现上来看CrDoCo这个方法超过了CyCADA,而且涨点还是比较多的,虽然我觉得他们俩本质上没啥区别,可能是参数调的好吧
10.Learning from Synthetic Data: Addressing Domain Shift for Semantic Segmentation(2018CVPR)pdf
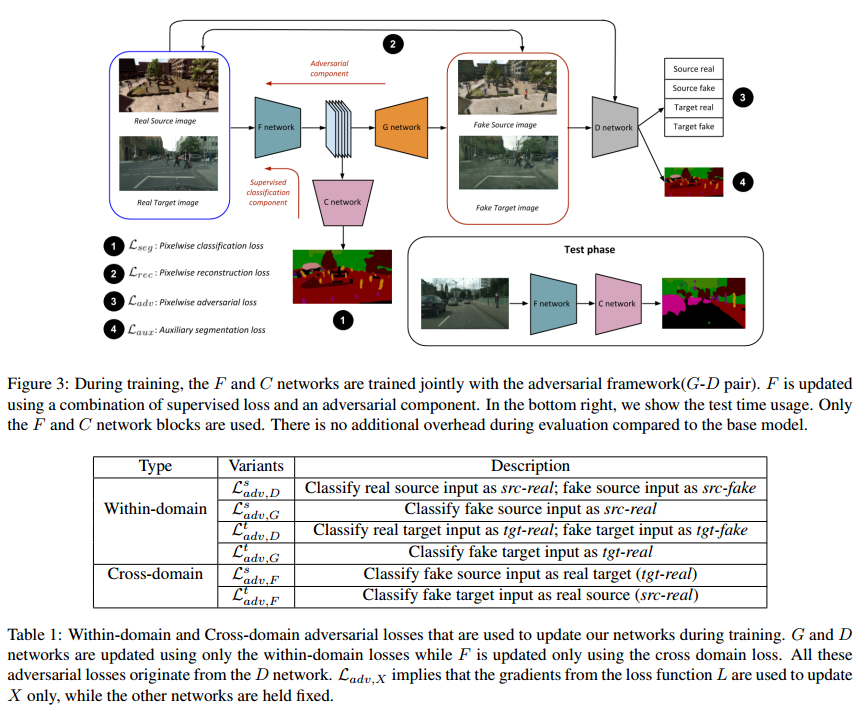
这个文章也是在GAN上面进一步深入,有意思的是这个文章把feature embedding的网络单独拆分开来,比起直接粗暴的在feature space上面加discriminator来减小source和target domain在feature space上的距离,这个文章用了一连串的adversarial loss来达到更好的效果,有种把GAN嵌到模型里的感觉,但对抗的也是真的复杂看晕我了
Method
直接上模型图
 更新过程
更新过程
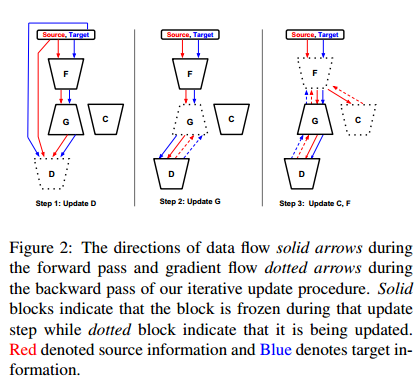 解释不动了,大家大概看看图能否理解吧,比较不同的就是他的这个D,看似是一个discriminator,但是还能出segmentation map的图,并不是一个简单的conv组成的小网络,按作者原话是根据GAN领域的最新发展,参考了Auxiliary Classifier GAN,所以要用一个conditioning generator和一个有辅助loss的discriminator可以获得更稳定的GAN,并且他们的G没有用noise,而是用dropouut来产生随机性的效果,这个算是文章比较不同的地方吧
解释不动了,大家大概看看图能否理解吧,比较不同的就是他的这个D,看似是一个discriminator,但是还能出segmentation map的图,并不是一个简单的conv组成的小网络,按作者原话是根据GAN领域的最新发展,参考了Auxiliary Classifier GAN,所以要用一个conditioning generator和一个有辅助loss的discriminator可以获得更稳定的GAN,并且他们的G没有用noise,而是用dropouut来产生随机性的效果,这个算是文章比较不同的地方吧
Results
结果也不多说了,反正涨点明显,毕竟2018年的时候sota表现还是比较差的,所以轻松涨点
11.Learning Semantic Segmentation from Synthetic Data: A Geometrically Guided Input-Output Adaptation Approach(2019CVPR)pdf
Assumption
文章的想法还是蛮简单的,就是提到了depth prediction和sementic segmentation是相关的任务,很多研究joint learning的paper都会把他们组合在一起,所以作者认为如果能利用好这两个任务的相关性,能够更好的来帮助domain adaptation,直观上的理解也确实,你给模型的信息信息越多,那模型学出来的东西就会更加的本质一点
Method
先直接来看模型图
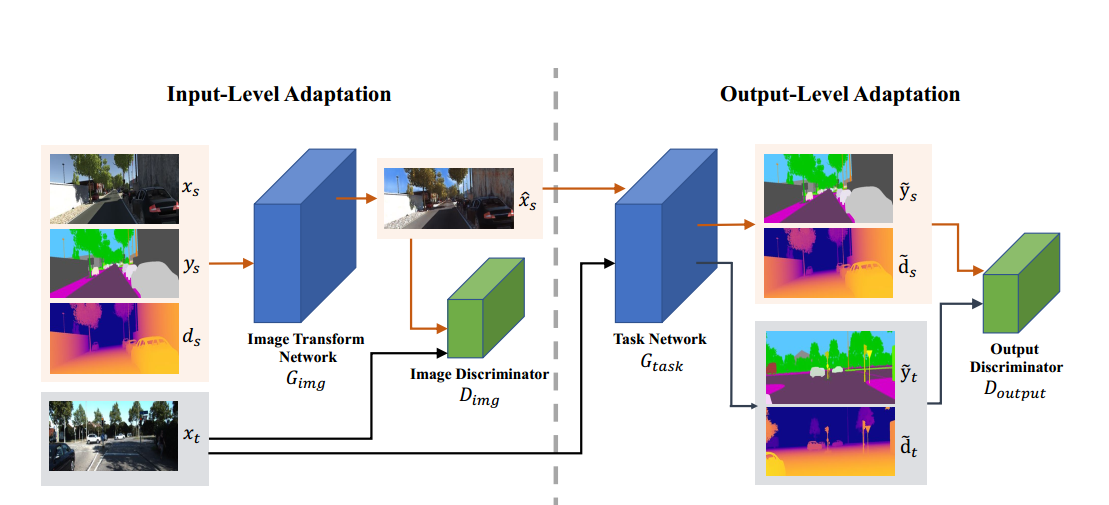 可以看到模型的结构上还是比较传统的,就是有一个image translation network(G)用来把source domain转换到target,为了训练这个G,仿照GAN用到了一个discriminator,然后转换过后的图片和target domain的图片都会被送到task network里面然后生成一个segmentation map和一个depth map,然后这两个map会被concatenate到一起给discrimintaor生成一个adversarial loss
这里的image translation network是整个大模型的一部分,是一个end-to-end的网络,generator一个是否保留住了原图的信息主要是靠task network的segmentation和depth estimation的loss
文章提到他们的方法主要是在input-level和output-level上面做adaptation,然后简单的解释了一下:
可以看到模型的结构上还是比较传统的,就是有一个image translation network(G)用来把source domain转换到target,为了训练这个G,仿照GAN用到了一个discriminator,然后转换过后的图片和target domain的图片都会被送到task network里面然后生成一个segmentation map和一个depth map,然后这两个map会被concatenate到一起给discrimintaor生成一个adversarial loss
这里的image translation network是整个大模型的一部分,是一个end-to-end的网络,generator一个是否保留住了原图的信息主要是靠task network的segmentation和depth estimation的loss
文章提到他们的方法主要是在input-level和output-level上面做adaptation,然后简单的解释了一下:
- Input-level Input-level的这个adaptation主要是为了减少视觉上的domain shift,加入depth的原因是因为depth能一定程度上减小几何信息的丢失并且depth和segmentation又很相关,这个generator的结构很简单,和cyclegan一样,我估计作者就是粗暴的把原图,depth map,segmentation map三个concatenate到了一起输给网络
- Output-level
output-level的adaptation主要的作用是两点:第一个是加入了depth estimation的任务能够使得网络对于domain shift更加的robust因为这个两个task共用一个encoder但是不同的decoder;第二点是这个两个任务之间的相关性可以看做是两个domain alignment之间重要线索。(其实这两个原因我觉得其实是一回事。。。)Task model的结构就是deeplab v2,backbone就是VGG16
Results
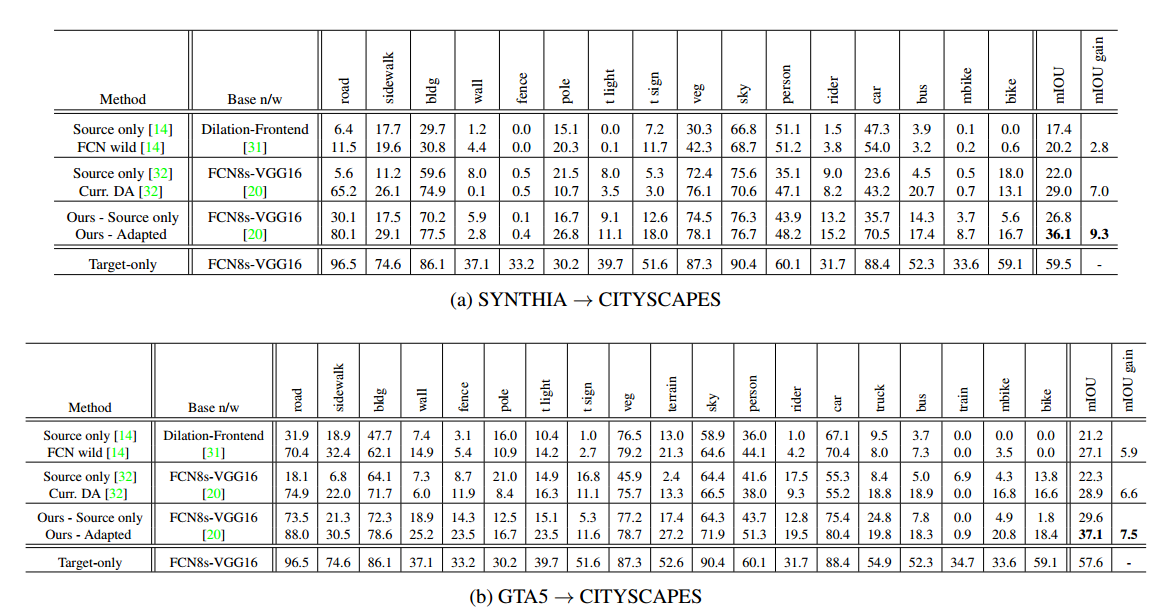
反正文章能发表,肯定是涨点了,但是这里我觉得有点问题就是用的模型和别的文章并不完全相同,虽然都是同一个backbone VGG16,但是deeplab v2和fcn-8s模型能力上还是存在区别的
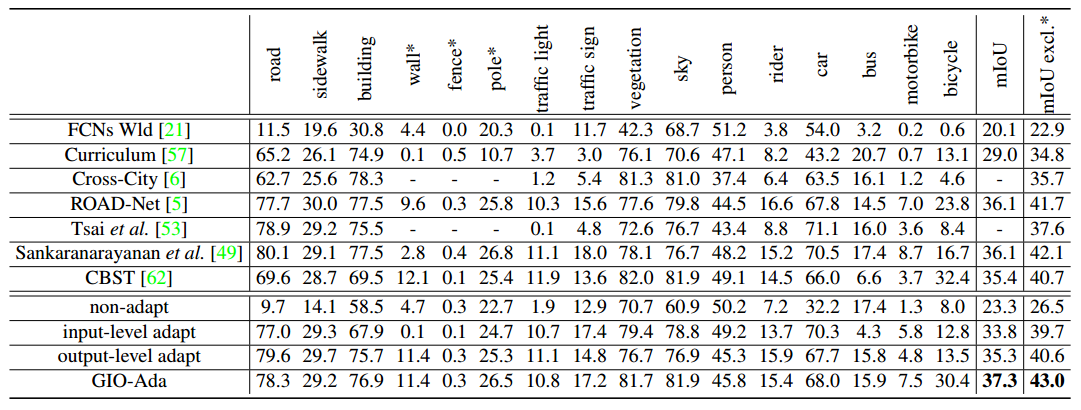 文章还做了一些ablation study我觉得还是比较有意思的,贴出来看看
文章还做了一些ablation study我觉得还是比较有意思的,贴出来看看 - Input-level
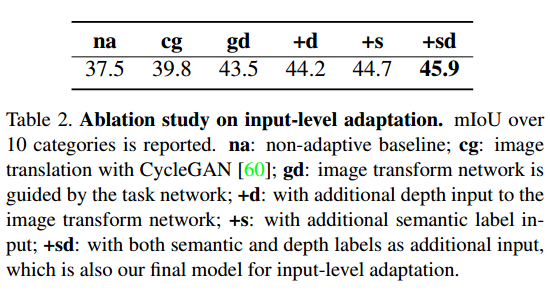 从这个表看出来,比起把image translation这个过程单独拿出去训练,文中采用端对段的这种网络,利用task loss来训练这个generator看起来效果更好(对比cg和gd),猜测可能是如果只是由source生成target,很难构建这个consistency loss,因为没有一个cycle的过程
从这个表看出来,比起把image translation这个过程单独拿出去训练,文中采用端对段的这种网络,利用task loss来训练这个generator看起来效果更好(对比cg和gd),猜测可能是如果只是由source生成target,很难构建这个consistency loss,因为没有一个cycle的过程 - Output-level
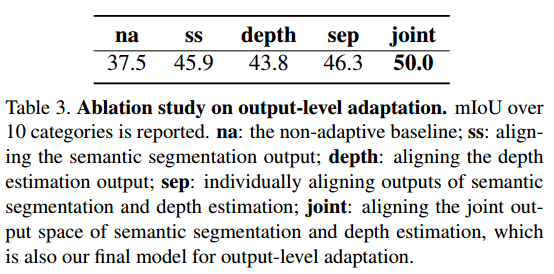
本来我还想吐槽这个output的discriminator居然就是粗暴的把segmentation map(c channels)和depth map(1 channel)组合成一个c+1 channel的map扔进去太粗暴了不应该分开来做两个loss么,结果发现人家做了实验对比,组合在一起效果更好虽然我也无法理解为什么会这样。。。我觉得难道是因为分开的话这两个adversarial loss还有权重的区别所以没调好?
12.DADA: Depth-aware Domain Adaptation in Semantic Segmentation(2019ICCV)pdf
这篇文章同样引入了深度信息来帮助进行domain adaptation,方法和上一个略有不同,主要是在feature-level上面进行domain adaptation
Assumption
文章的假设就两点:第一引入了privileged information的概念,就是说网络得到的信息越多,训练的就越好就像人的接受新事物的时候都会有老师帮助解释这样子;第二点是说因为是针对的是自动驾驶的数据集,所以那些离相机更近的物体应该更加重视,毕竟离得比较远的即使错了对于自动驾驶来说也问题不大
Method
直接上模型图
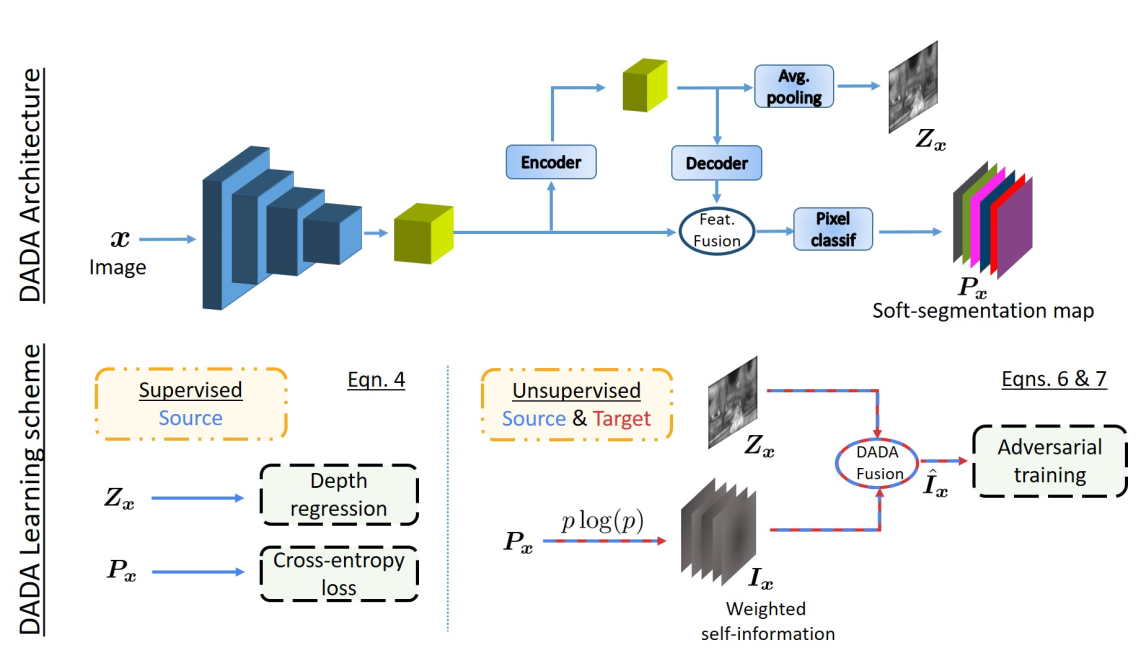 大概解释一下,就是给模型直接输入一个图片,然后这里有一个backbone的CNN来提取特征,提取完特征之后,会有一个额外的encoder(3层conv)进一步对这个提取出来的特征做处理,看了看代码主要是降低维度,backbone的结果都是2048channel的,这个拿去预测depth维度太高了,所以用这个encoder把维度降到128,然后进行average pooling的操作就是对每个pixel上面的所有通道求个均值做的depth的预测结果。同时这个128维的feature还有一个decoder(1层conv),其实就是把维度还原成2048,然后和原来的feature做一个element-wise product得到融合的feature,再拿这个feature拿去做segmentation预测。
想法还是很清晰的,就是想把用于预测depth学到的特征融合进来,提高feature space的鲁棒性。当然模型最后也在output space上面做了一个adversaraial loss,利用对source image和target image预测的两个深度图和分割图,做了一个DADA fusion,解释一个就是和advent文章一样,先把分割图转转换成1通道的entropy map,然后再和深度图直接做element-wsie product,这里提一下因为深度预测的任务大家一直都是预测的深度的倒数,因为有一些物体类似于天空是无穷远不用倒数不好表达,所以这里和深度的倒数做乘积,刚好作者说能够使得近处的物体数值变大,表示更加重视近处物体,符合第二个假设
大概解释一下,就是给模型直接输入一个图片,然后这里有一个backbone的CNN来提取特征,提取完特征之后,会有一个额外的encoder(3层conv)进一步对这个提取出来的特征做处理,看了看代码主要是降低维度,backbone的结果都是2048channel的,这个拿去预测depth维度太高了,所以用这个encoder把维度降到128,然后进行average pooling的操作就是对每个pixel上面的所有通道求个均值做的depth的预测结果。同时这个128维的feature还有一个decoder(1层conv),其实就是把维度还原成2048,然后和原来的feature做一个element-wise product得到融合的feature,再拿这个feature拿去做segmentation预测。
想法还是很清晰的,就是想把用于预测depth学到的特征融合进来,提高feature space的鲁棒性。当然模型最后也在output space上面做了一个adversaraial loss,利用对source image和target image预测的两个深度图和分割图,做了一个DADA fusion,解释一个就是和advent文章一样,先把分割图转转换成1通道的entropy map,然后再和深度图直接做element-wsie product,这里提一下因为深度预测的任务大家一直都是预测的深度的倒数,因为有一些物体类似于天空是无穷远不用倒数不好表达,所以这里和深度的倒数做乘积,刚好作者说能够使得近处的物体数值变大,表示更加重视近处物体,符合第二个假设
Results
只做了SYNTHIA-Cityspaces一组实验,结果如下
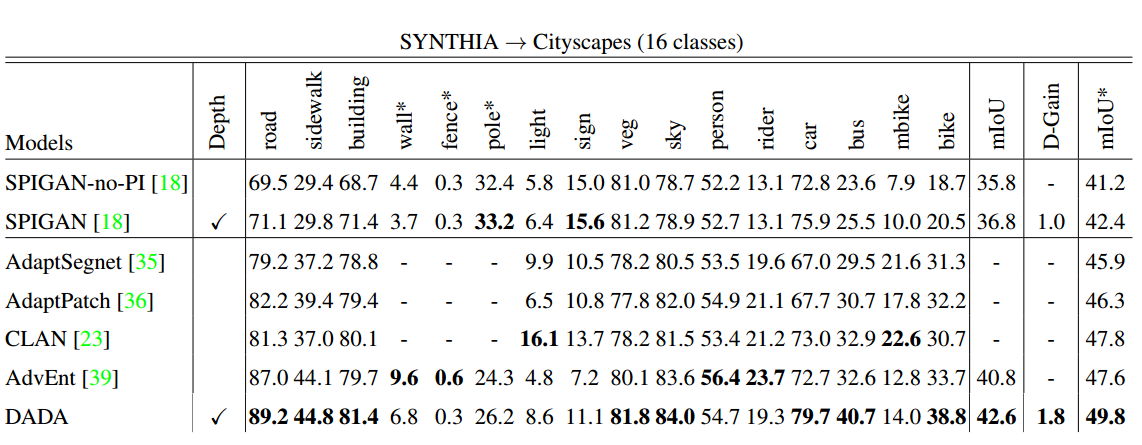 可以看到还是有一些涨点的,但是有个很奇怪的地方,就是全文一直在cue SPIGAN这个文章,仿佛是第一个把depth引入domain adaptation for segmentation的文章,作者一直说他们的方法超过了SPIGAN,但是从结果来看,他俩又不同台竞技,用的一个模型,却用的不同backbone,SPIGAN用的VGG16,但是本文用的resnet101。作者明明可以再跑个VGG16的结果,但是没有,盲猜并没有打败前人,所以干脆换个赛道。。。
可以看到还是有一些涨点的,但是有个很奇怪的地方,就是全文一直在cue SPIGAN这个文章,仿佛是第一个把depth引入domain adaptation for segmentation的文章,作者一直说他们的方法超过了SPIGAN,但是从结果来看,他俩又不同台竞技,用的一个模型,却用的不同backbone,SPIGAN用的VGG16,但是本文用的resnet101。作者明明可以再跑个VGG16的结果,但是没有,盲猜并没有打败前人,所以干脆换个赛道。。。
13.Domain Adaptation for Semantic Segmentation with Maximum Squares Loss(2019ICCV)pdf
这个文章可以理解为就是AdaSeg,Advent的进阶,主要是针对Advent里面那个entropy minization loss在high confidence cases上面梯度较大的改进,提出了high confidence意味着就是easy case,所以在这种case上面gradient很大没有意义,所以需要尽量平均一下gradient
Method
文章是一个non-adversarial的结构,这个还比较少见,下面介绍一个文章的主要观点这个maximum square loss,
先看entropy minimization loss和对应的在二分类问题上的gradient
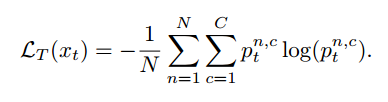
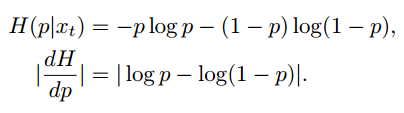 再看提出的maximum square loss和对应的在二分类问题上的gradient
再看提出的maximum square loss和对应的在二分类问题上的gradient
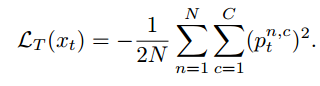
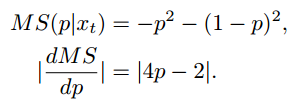 然后作者画了个随着这个confidence score的变化,graident mganitude的变化
然后作者画了个随着这个confidence score的变化,graident mganitude的变化
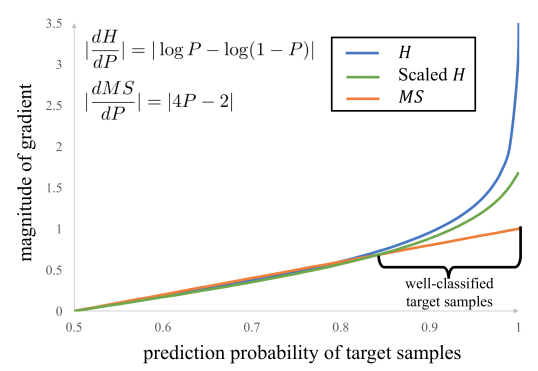 可以看到entropy minimization的方法在high confidence case上面的梯度会呈指数上升,而maximum square loss就始终是一个线性的方法,相比较而言会好一点,因为对于那些本来confidence score就很高比如已经0.95的case来说,进一步把他们提升到1.0其实对于预测本身来说没啥收益,因为反正最后还要来个argmax,所以结果都是一样的,所以我们就希望网络不要老是在学这个没啥意义的工作
当然文章除了这个maximum square loss以外,还有一些修修补补的小工作,比如说提出了一个Image-wise Class-balanced Weighting Factor,意思就是说对于target domain image来说每一类的占比不是一样的,那些多的类就很容易学的比较好因为loss会比较大,所以我们要处理一下这个类间的不平衡问题,如果有label的话,那这个问题就很naive,直接用每一类的占比取个倒数乘到前面就好,甚至可以参考focal loss,但是问题是target domain我们没有label,所以有些文章就会用source domain的这个统计参数,但是source domain和target domain在这个统计参数上其实并不是一定一样的,所以文章就提到还是要用target domain的统计参数,就是使用实际模型对于target domain的预测图来算这个统计参数,这又有了新问题,就是模型的预测结果并不一定准确,所以作者就弄了个缩放系数,当成一个超参来调整,具体公式如下
可以看到entropy minimization的方法在high confidence case上面的梯度会呈指数上升,而maximum square loss就始终是一个线性的方法,相比较而言会好一点,因为对于那些本来confidence score就很高比如已经0.95的case来说,进一步把他们提升到1.0其实对于预测本身来说没啥收益,因为反正最后还要来个argmax,所以结果都是一样的,所以我们就希望网络不要老是在学这个没啥意义的工作
当然文章除了这个maximum square loss以外,还有一些修修补补的小工作,比如说提出了一个Image-wise Class-balanced Weighting Factor,意思就是说对于target domain image来说每一类的占比不是一样的,那些多的类就很容易学的比较好因为loss会比较大,所以我们要处理一下这个类间的不平衡问题,如果有label的话,那这个问题就很naive,直接用每一类的占比取个倒数乘到前面就好,甚至可以参考focal loss,但是问题是target domain我们没有label,所以有些文章就会用source domain的这个统计参数,但是source domain和target domain在这个统计参数上其实并不是一定一样的,所以文章就提到还是要用target domain的统计参数,就是使用实际模型对于target domain的预测图来算这个统计参数,这又有了新问题,就是模型的预测结果并不一定准确,所以作者就弄了个缩放系数,当成一个超参来调整,具体公式如下
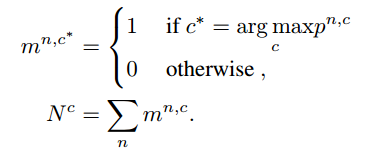
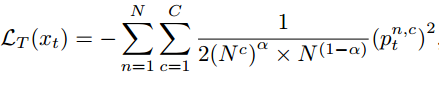 其中的这个alpha就是超参
最后一点就是作者除了最终出一个final segmentation map以外,还在low-level feature也预测了一个map,然后对于这个map生成了一个pseudo label,用的方法就是对final segmentation map和low-level segmentation map同时拉一个阈值寻找那些一定对的点
其中的这个alpha就是超参
最后一点就是作者除了最终出一个final segmentation map以外,还在low-level feature也预测了一个map,然后对于这个map生成了一个pseudo label,用的方法就是对final segmentation map和low-level segmentation map同时拉一个阈值寻找那些一定对的点
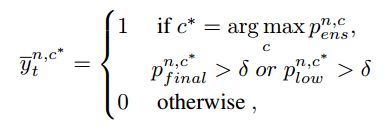 大家有兴趣可以自行看看原文
大家有兴趣可以自行看看原文
Results
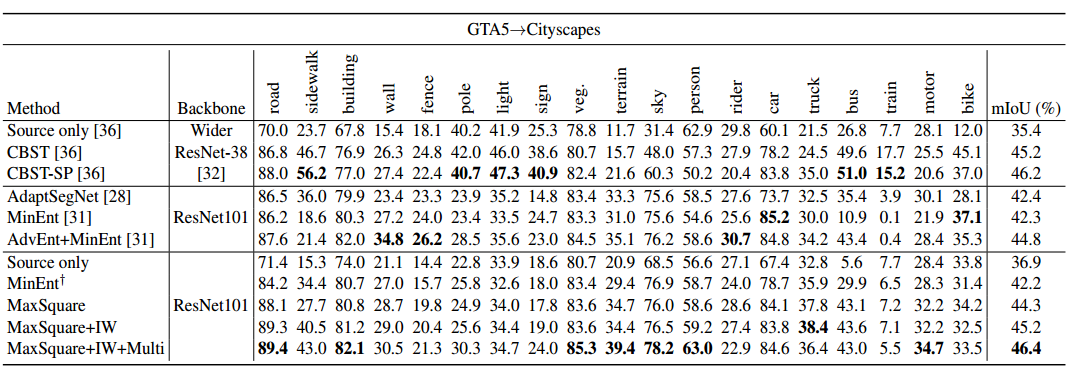
可以看到文章其实主要在和Advent来比,然后还是有一些涨点的吧,虽然并不是很明显,但文章主要是一个non-adversarial的方法
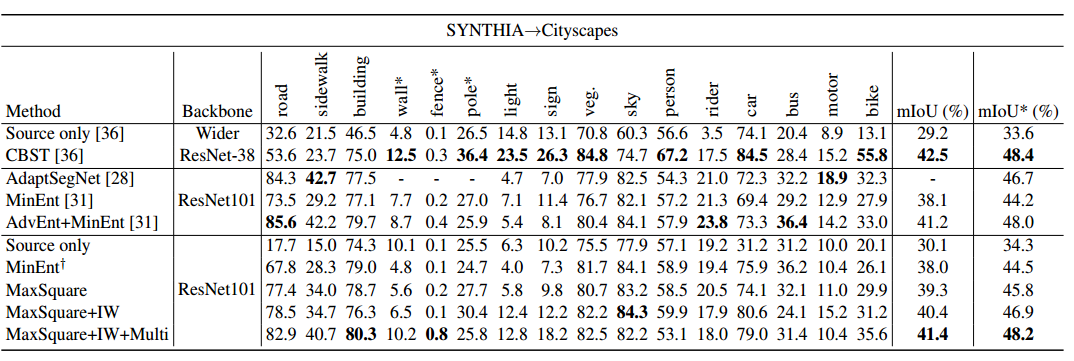
14.SSF-DAN: Separated Semantic Feature based Domain Adaptation Network for Semantic Segmentation(2019ICCV)pdf
这个文章的idea还是比较自然的,就是在feature-level上面进行domain adaptation,整体的把一个feature map送给discriminator来分辨,这样其实没有区别对待不同的class,所以就想到了要分开来每一个class弄一个discriminator来做对抗训练
Method
先上模型结构图
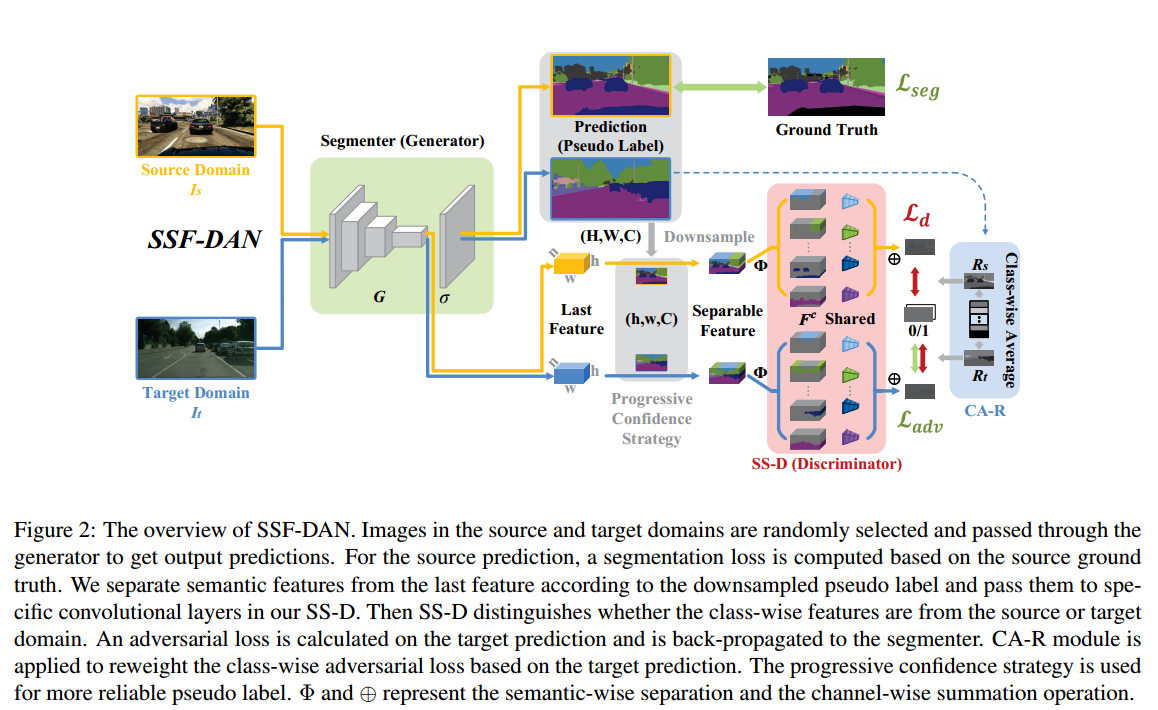 简单的理一下这个模型的结构,前面的部分G可以理解为是一个feature extracter,然后sigma就是一个decoder,decoder的结果就是segmentation map,用来做一个cross entropy loss。G提出来的feature和segmentation map相乘,得到每一类各自的feature map(source用gt,target用prediction),然后每一个有各自的一个discriminator(SS-D部分),最终把所有discriminator的结果全部相加,得到最终的对于feature map的pixel-wise的判断结果,判断每个点的feature是属于source还是target,以此来做一个对抗训练。
文章还有一些细节,这些细节主要是用于处理target domain没有gt,所以去分割feaeture的时候会存在使用的prediction结果存在错误的问题,所以作者提出了一些修修补补的东西来尽量减小这些错误。
简单的理一下这个模型的结构,前面的部分G可以理解为是一个feature extracter,然后sigma就是一个decoder,decoder的结果就是segmentation map,用来做一个cross entropy loss。G提出来的feature和segmentation map相乘,得到每一类各自的feature map(source用gt,target用prediction),然后每一个有各自的一个discriminator(SS-D部分),最终把所有discriminator的结果全部相加,得到最终的对于feature map的pixel-wise的判断结果,判断每个点的feature是属于source还是target,以此来做一个对抗训练。
文章还有一些细节,这些细节主要是用于处理target domain没有gt,所以去分割feaeture的时候会存在使用的prediction结果存在错误的问题,所以作者提出了一些修修补补的东西来尽量减小这些错误。
- Progressive Confidence Strategy 这里就是说我们对于target domain image的pseudo label不能全信,所以需要找个方法滤掉一部分不靠谱的。作者的方法是:因为在模型训练的初期,模型的预测能力很差,所以生成的pseudo label也大多不靠谱,所以我们保留的pseudo label因为随着训练的进程,逐渐变多。因此作者设置了一个超参代表保留的点的数量的比例,即对生成的label里面每个点的confidence从高到低排列,然后只保留最高的部分点的结果
- Class-wise Adversarial Loss Reweighting
这个主要用于处理类间不平衡的问题,想要加大那些不容易得到high confidence的类的loss权重,用的方法就是算了个每一类实际预测的时候的平均分数的倒数开根号乘到loss里面,举个例子比方说一个二分类,有100个点被预测为0,平均的score是0.9,有100个点被预测为1,平均score是0.6,那么0类的权重就是sqrt(1/0.9)
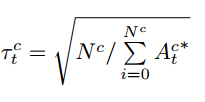
Results
结果上就是涨点了
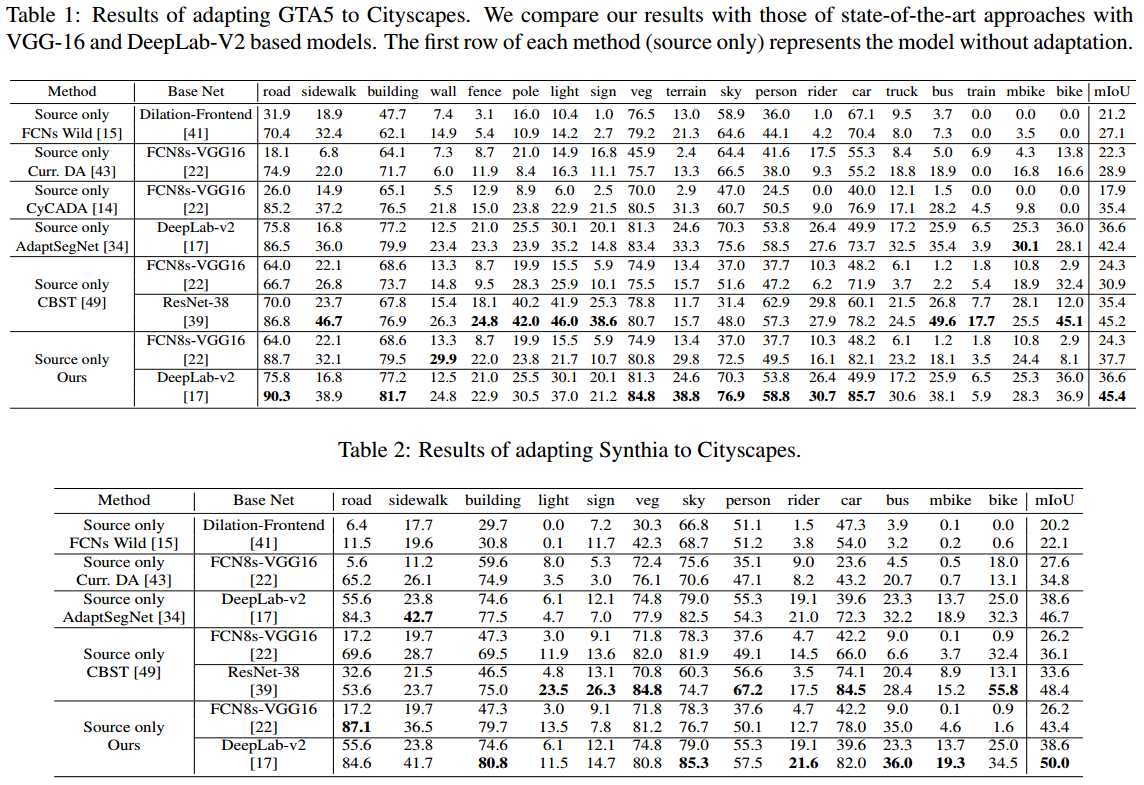 同模型和Adaseg比较,可以感觉到在那些比较难的类上面是有一定的涨点的虽然不是很明显,例如sign和pole。很奇怪的是,在car这个大类上面,反而涨点最明显,也是玄学了,意思是分开来做adaptation对car的帮助最大。
同模型和Adaseg比较,可以感觉到在那些比较难的类上面是有一定的涨点的虽然不是很明显,例如sign和pole。很奇怪的是,在car这个大类上面,反而涨点最明显,也是玄学了,意思是分开来做adaptation对car的帮助最大。